

By Alex Lio — The Procurementor. Special edition.
Two years ago, AI was a rounding error on most European P&Ls. A few ChatGPT Plus subscriptions buried in expense reports, nobody tracking anything. Today, it’s one of the fastest-growing SaaS lines in the house — and the trajectory isn’t flattening anytime soon.
Every new agent you deploy, every workflow you automate, every extra use case burns tokens that didn’t exist the month before. Three years from now, AI will probably sit among the top three SaaS line items for mid-cap companies — somewhere next to Microsoft 365 or Salesforce.
The problem? Nobody has a real handle on how this market moves. New players show up every quarter (xAI, DeepSeek, Mistral, and Perplexity all went from nothing to serious in 18 months). New models ship almost every month, with prices diverging by a factor of 50 depending on the tier. New ways to consume keep appearing — subscriptions, APIs, agents, routers, self-hosted open source. Whatever vendor map you’ve drawn today is out of date by Q4.
Even when you think you’re locked in with the best option, things shift fast: see how the narrative swung back toward OpenAI after a year of Claude running the enterprise conversation.
In that kind of market, asking the boring questions now — what are we buying, how, from whom, for what use — isn’t an intellectual exercise. It’s the difference, three years out, between the companies that still control their AI spend and the ones staring at a bill they can’t explain.
This article is a detour from my S2P × AI series. Before talking about an agent that drafts your contracts or pays your invoices, we need to talk about what it actually costs to run this stuff. Most organisations I walk into jump straight from “AI is amazing” to “we burned 300 k€ and nobody knows on what” without the middle step: understanding how you buy AI in the first place.
If you’ve been around long enough, this should feel familiar. Cloud, 2015. Remember? The AWS bill that blew up in Q1 because a developer left an EC2 instance running for three months. We all learned. We’re about to relearn the same lesson — except faster, with bigger numbers, and with tooling that doesn’t really exist yet.
This piece is a bit longer than usual. On purpose. No CPO or CFO can afford to wave this topic off in 2026, and skipping it today just means taking it in the face six months from now.
What you’re actually buying: tokens, inference, and the cost logic
Before we get to negotiation, we need to talk about the unit of measure. And that unit isn’t “a Copilot licence” or “a Claude seat.” It’s the token.
A token is roughly a chunk of a word. “Hello” = 1 token. “Procurementor” = 3 to 5 tokens. Every request you send to an LLM consumes input tokens (your prompt, any attached files, the conversation history) and produces output tokens (the answer). You pay for both. Prices in 2026 run from about $0.10 to around $25 per million tokens (up to ~$40 on some premium reasoning models) depending on the model — so somewhere around $0.000001 per token, give or take a zero.
The number looks laughably small. Right up until an agent starts churning through 40 million tokens a day in the background with nobody watching.
Inference is the act of running the model to get an answer. The cost scales with the tokens processed, but also with the horsepower of the model you pick. An “extended reasoning” model that thinks for 40 seconds can burn 10 to 50 times more tokens than a fast one — sometimes for a barely noticeable bump in quality.
The one thing to remember: your AI spend is driven by three variables — volume of requests, length of prompts and responses, and the power of the model you pick. In most projects I’ve seen, all three are oversized by default.
The vendor landscape: all different, all interchangeable?
Four big players dominate the enterprise market in April 2026:
- Anthropic (Claude) — Haiku, Sonnet, Opus (4.6/4.7) family. Strong on long-form reasoning and following instructions. Transparent pricing, mature on technical use cases.
- OpenAI (ChatGPT, GPT-5, o-series) — the most widely installed in companies. Broad ecosystem, fast release cadence, quality varies from version to version.
- Google (Gemini) — wins on context size, Workspace integration, and aggressive pricing on high volumes.
- xAI (Grok) — outsider catching up, especially on real-time and search-heavy use cases.
Beyond the brand names: LLMs are not interchangeable at equal quality and equal cost. A Sonnet 4.6 is not a GPT-5 — not in capability, not in price, not in style. And even within a single family, the gap between Haiku (fast, cheap) and Opus (deep, expensive) can hit 5× in price on use cases where Haiku would have been plenty.
Concrete example, April 2026, back-of-envelope. A customer service agent handling 1,000 conversations a day — on average 1,500 input tokens (message + context + knowledge base) and 250 output tokens per conversation. On Haiku 4.5: about 80 €/month. On Opus 4.6/4.7: about 375 €/month. ~5× difference, same agent, same prompt, same perceived quality in 95 % of customer service cases — where running Opus is just waste.
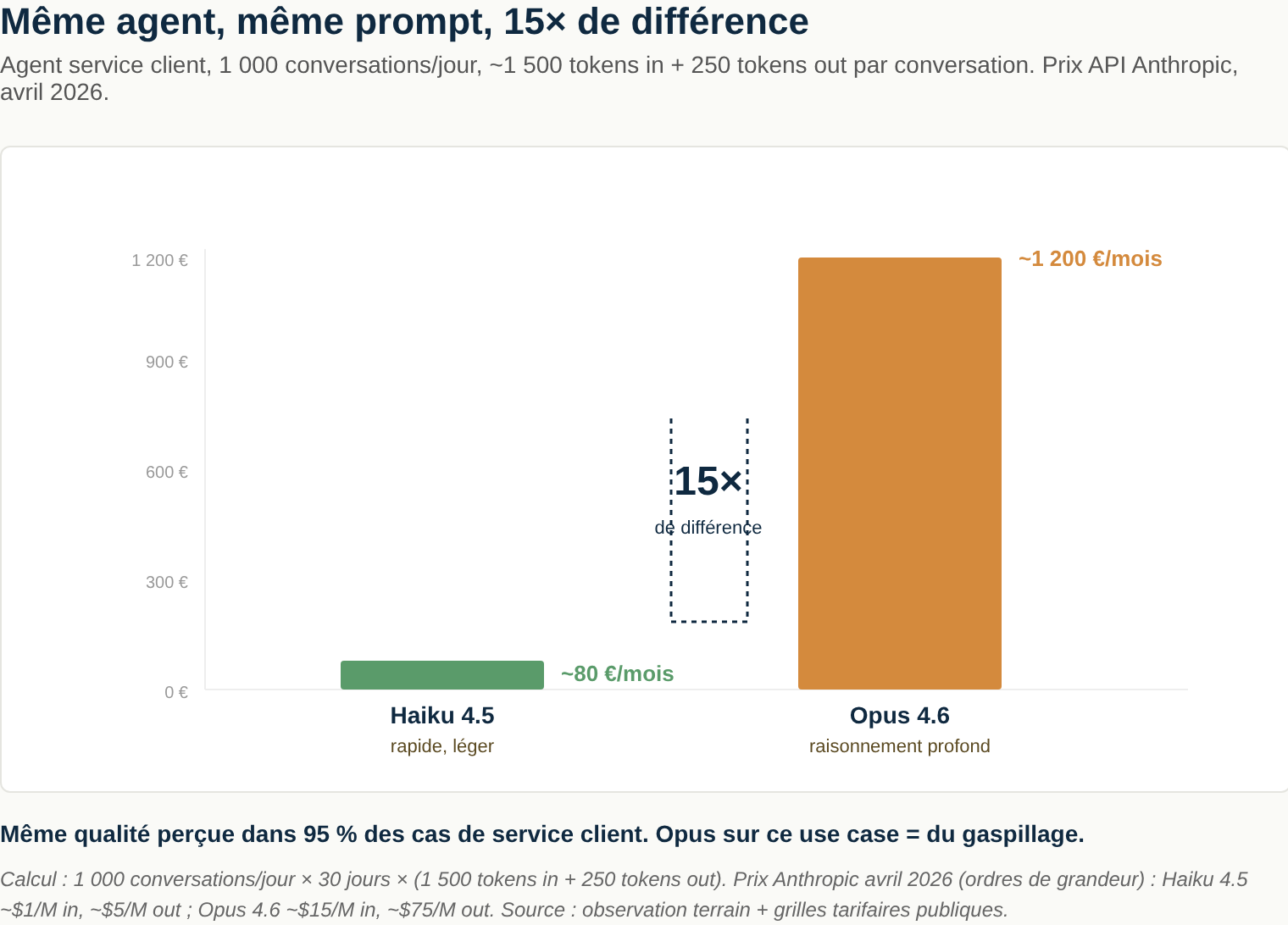
The procurement rule: never buy “Claude” or “ChatGPT.” Buy a specific model for a specific use case. An agent categorising invoices doesn’t need Opus. A contract analysis tool probably shouldn’t run on Haiku.
If your vendor conversation doesn’t go to that level of detail, you’re paying top price by default. And the sales teams on the other side of the table won’t volunteer to migrate 70 % of your usage to a model that’s 10× cheaper.
Subscription vs API: two faces of the same bill
This is where 80 % of the disasters happen. There are two ways to buy AI, and they are nothing alike on the financial risk side.
Subscription. You pay a flat fee per month, per user. Claude Pro at $20/month, ChatGPT Enterprise at around $60/seat/month, and so on. Fixed ceiling, capped consumption, the user gets blocked when they hit the quota. It’s predictable, transparent, and relatively safe on the finance side. It’s also what most teams use today for individual assistants in a browser or app.
To give you a concrete sense of scale — here’s what 20 € and 100 € a month buy you in April 2026:
| Budget/month | Mode | Anthropic | OpenAI | |
|---|---|---|---|---|
| ~20 € | Subscription | Claude Pro — ~1-2 M token equivalent | ChatGPT Plus — ~1-2 M token equivalent | Gemini Advanced — ~2-3 M token equivalent |
| ~20 € | API pay-as-you-go | Sonnet 4.6 — ~2 M tokens | GPT-5 — ~3 M tokens | Gemini 2.5 Pro — ~6 M tokens |
| ~100 € | Subscription | Claude Max 5× — ~5-10 M tokens | ChatGPT Business (seats) — variable | Gemini Advanced multi-seat |
| ~100 € | API pay-as-you-go | Sonnet 4.6 — ~10 M tokens | GPT-5 — ~16 M tokens | Gemini 2.5 Pro — ~32 M tokens |
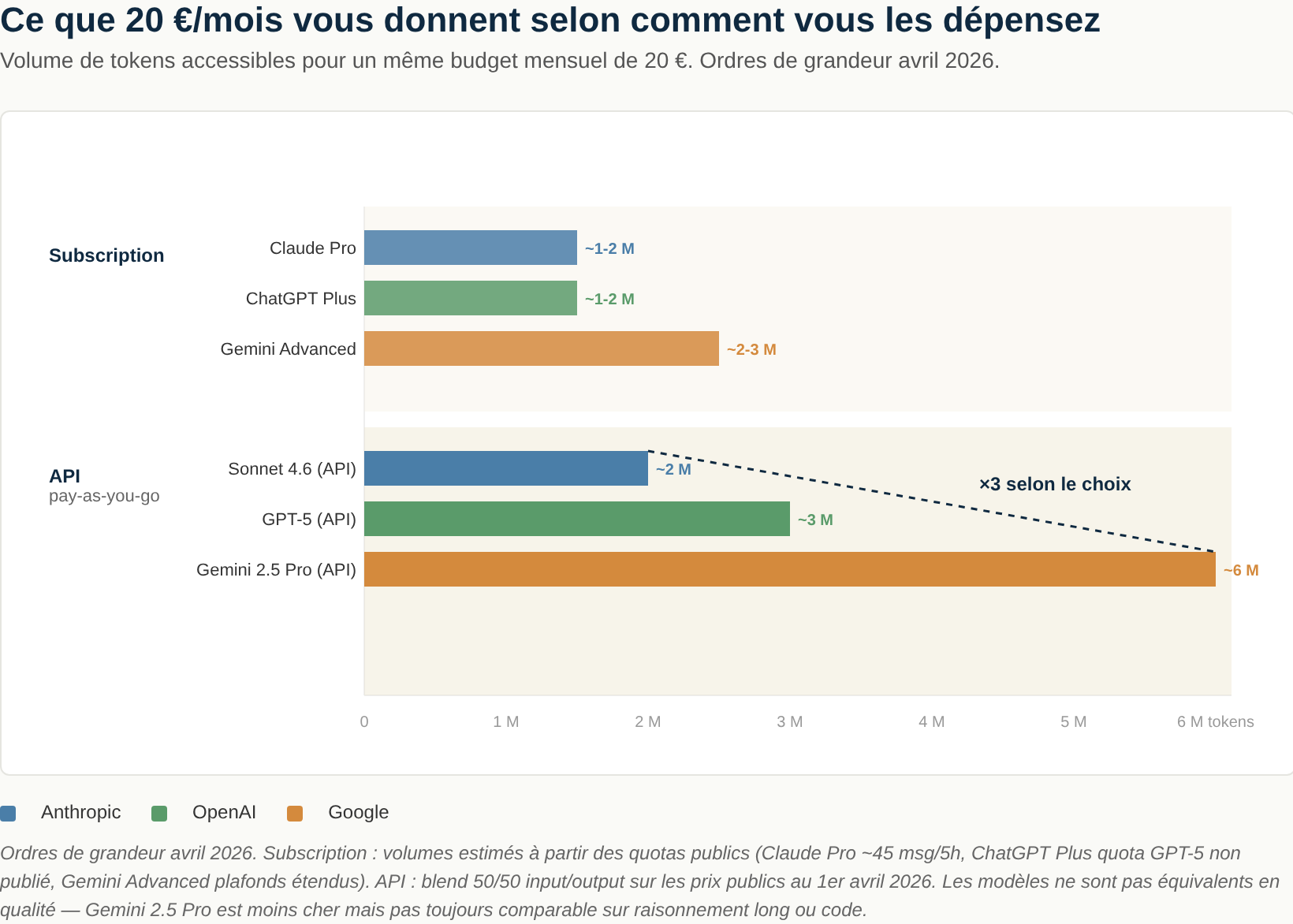
What to take away: past a certain volume, the API beats the subscription on €/token every time — unless you’re willing to live with individual usage ceilings. The real question isn’t “API vs subscription,” it’s “what mix for which user profile.”
API. You stop paying per user. You pay per token consumed. The software in your company — internal agents, automations, customer-facing chatbots, data scripts — calls the API directly. No seat. No ceiling. No human to stop when things go sideways. This is where the six-figure bills come from.
Go scroll LinkedIn for a minute. Founders proudly posting their $100k+ OpenAI bill for a team of 5. That could easily be a red flag, not a flex. A badly calibrated agent can burn through thousands of euros in a few hours. The stories are piling up:
- A developer kicks off a scraping agent with a sloppy prompt. The agent loops on itself for a whole night. Morning bill: $34,000.
- A marketing team tests a content generation tool. The default template sends the entire website as context with every request. $800 a day, for three weeks, before anyone notices.
Governance rule: anyone in your organisation with an API key needs a technical budget cap (not just a contractual one). Alert at 50 %, at 80 %, automatic kill switch at 100 %. Without that, you’re playing roulette with your P&L.
Nobody applies this by default. It’s an explicit decision, ideally owned jointly by procurement, finance, and IT. Otherwise it just doesn’t happen.
The optimisation levers: routers, open source, right model for the job
AI routers. A router is a software layer that sends every request to the most appropriate model in real time (or the cheapest one at the quality bar you set). Claude is down? Fall back on GPT-5. Simple request? Route it to Haiku instead of Opus. Self-hosted open source model good enough? Use that first. It’s also a live experimentation ground: same request sent to 3 providers, you compare the outputs, you pick data-driven.
OpenRouter, LiteLLM, Portkey and a handful of others dominate this segment in 2026. For any organisation spending more than about 100 k€/year on AI, this isn’t optional anymore — it’s basic hygiene. Typical savings: 30 to 60 % at equal quality, plus resilience when a provider goes down — which has happened several times at each of the big players in 2025.
Open source models. Llama (Meta), Mistral (French, and yes I’m biased), DeepSeek, Qwen and a few others put out surprisingly good models — often at near-zero marginal cost if you self-host. The idea isn’t to pay per token, it’s to build your own capacity to handle the demand. It’s not always the right call — self-hosting costs engineering time, GPU infrastructure, and ML know-how. But on volume-heavy, repetitive use cases (categorisation, extraction, classification, RAG over internal data), a fine-tuned Mistral can replace Claude Sonnet for a twentieth of the cost, with lower latency, and your data never leaves your servers. If you have a mature data or ML team, this is probably your single biggest lever in 2026.
The general principle: the cheapest AI that gets the job done is the right one. Not the most powerful. Not the most hyped on X. The one that does the job at acceptable quality for the minimum cost. It’s a banal principle in classic procurement, and yet everyone forgets it the moment AI comes up. Probably because the topic still feels tech / strategic / innovation, when in reality it’s quietly becoming just another budget line. One that moves 10× faster than the rest.
The tooling: the emerging SaaS/AI FinOps market
A new category is forming in 2025-2026: platforms specialised in AI and SaaS spend management. Because between AI subscriptions, classic SaaS subscriptions (which themselves now ship more and more AI features billed separately), API costs, user licences and overages — nobody knows who’s paying for what anymore. Three players worth knowing:
- Spendhound (US) — free for the client. You plug in your SaaS vendor accounts, the tool tells you which renewals are coming up, where the benchmarks sit, and what negotiation levers you have. One caveat on the business model: Spendhound is backed by a marketing company that monetises the vendor “sentiment” data collected from its clients. Not a problem in itself — it’s how Gartner and G2 work — but worth knowing before you hand over contract data.
- Vertice (UK, strong unicorn candidate) — paid, but “white glove”: their team actually negotiates your SaaS and AI contracts on your behalf, leveraging the benchmarks they’ve built from their other clients. ROI usually covers the cost for companies spending more than 5 M€/year on SaaS.
- Najar (French, formerly Welii) — growing European alternative, pragmatic positioning, useful if you want a vendor inside your GDPR jurisdiction with a local point of contact.
Or the premium human option: bring in a procurement consultant who understands these technologies, can point you to the right choices, and help you tighten your contracts — commitment ceilings on API consumption, data portability clauses, audit rights on usage logs, clean exit clauses, reversibility to a competitor. Happy to chat: alex@theprocurementor.com. 😉
If your organisation is starting to see its AI costs slip and you want an outside procurement × tech pair of eyes on it: alex@theprocurementor.com.