

Par Alex Lio — The Procurementor. Article hors-série.
En 2024, les coûts IA étaient un petit budget, ignoré et invisible dans la majorité des boîtes européennes. En 2026, c’est devenu l’une des lignes SaaS à plus forte croissance — avec une trajectoire qui ne va pas s’inverser.
Chaque nouvel agent déployé, chaque workflow automatisé, chaque cas d’usage supplémentaire consomme des tokens qui n’existaient pas le mois d’avant. Dans trois ans, l’IA sera probablement l’un des trois plus gros postes SaaS des ETI — au même niveau qu’un Microsoft 365 ou un Salesforce.
Le problème, c’est que personne ne maîtrise vraiment la dynamique du marché. De nouveaux acteurs émergent chaque trimestre (xAI, DeepSeek, Mistral, Perplexity ont tous explosé en 18 mois). De nouveaux modèles sortent quasiment chaque mois, avec des prix qui divergent d’un facteur 50 selon les tiers. De nouvelles manières de consommer apparaissent (subscription, API, agents, routers, open source auto-hébergé). Le paysage que vous connaissez aujourd’hui ne sera plus le même dans six mois.
Même quand on pense travailler avec le meilleur acteur, les choses changent très rapidement : voir le retour vers OpenAI après l’hégémonie de Claude.
Dans ce contexte, se poser maintenant les bonnes questions — qu’est-ce qu’on achète, comment, à qui, pour quel usage — n’est pas une curiosité intellectuelle. C’est ce qui différenciera, dans trois ans, les organisations qui auront gardé le contrôle de celles qui auront une facture qu’elles ne savent plus expliquer.
Cet article est un détour hors de ma série S2P × IA. Parce qu’avant même de parler d’un agent qui rédige vos contrats ou qui paye vos factures, il faut parler de ce que coûte, concrètement, faire tourner tout ça. Et la majorité des organisations que je vois passent directement de « l’IA c’est incroyable » à « l’IA on y a perdu 300 k€ » sans la case intermédiaire : comprendre comment on achète l’IA.
C’est exactement comme la première fois que votre boîte a acheté du cloud en 2015. Vous vous rappelez ? La facture AWS qui explose au Q1 parce qu’un dev a oublié une instance EC2 en mode « on » pendant trois mois. On a tous appris. On va devoir réapprendre. Avec un twist : ça va plus vite, les montants sont plus gros, et l’outillage de contrôle n’existe pas encore vraiment.
Cet article est volontairement un peu plus long que d’habitude. Parce que c’est un sujet qu’aucun CPO ni aucun CFO ne peut ignorer en 2026, et que le zapper c’est le prendre dans la figure six mois plus tard.
Comprendre ce qu’on achète : token, inference, et la logique des coûts
Avant de parler de négociation, il faut parler de l’unité de base. Et cette unité, ce n’est pas « une licence Copilot » ni « une seat Claude ». C’est le token.
Un token, c’est à peu près un morceau de mot. « Bonjour » = 1 token. « Procurementor » = 3 à 5 tokens. Chaque requête que vous envoyez à un LLM consomme des tokens en entrée (votre prompt, les fichiers joints, l’historique de la conversation) et produit des tokens en sortie (la réponse). Chaque token est facturé. Les prix varient selon le modèle, dans une fourchette qui va de ~0,10 $ à ~25 $ par million de tokens en 2026 (jusqu’à ~40 $ sur certains modèles de raisonnement premium) — soit ~0,000001 € par token (à un ou deux zéros près).
Ce chiffre paraît ridiculement faible. Jusqu’à ce qu’un agent se mette à traiter 40 millions de tokens par jour, en arrière-plan, sans que personne ne regarde.
L’inference, c’est l’acte de faire tourner le modèle pour produire une réponse. Le coût est proportionnel aux tokens traités, mais aussi à la puissance du modèle utilisé. Un modèle « raisonnement étendu » qui pense pendant 40 secondes peut consommer 10 à 50 fois plus de tokens qu’un modèle rapide — pour parfois un gain de qualité marginal.
Retenez ça : le coût IA d’une organisation est proportionnel à trois variables — volume de requêtes, longueur des prompts et réponses, puissance du modèle choisi. Dans la plupart des projets et usages, les trois sont surdimensionnées par défaut.
Le paysage des fournisseurs : tous différents, tous interchangeables ?
Quatre grands acteurs dominent le marché enterprise en avril 2026 :
- Anthropic (Claude) — famille Haiku, Sonnet, Opus (4.6/4.7). Réputés pour la qualité du raisonnement long et le respect des consignes. Tarification transparente, modèles matures sur les cas techniques.
- OpenAI (ChatGPT, GPT-5, o-series) — le plus installé dans les entreprises. Écosystème large, rythme de release élevé, qualité variable selon les versions.
- Google (Gemini) — différenciant sur la taille du contexte, l’intégration Workspace, et des prix agressifs sur les gros volumes.
- xAI (Grok) — outsider qui progresse, surtout sur les cas temps réel et recherche.
Au-delà des marques : les LLM ne sont pas interchangeables à qualité égale pour le même coût. Un Sonnet 4.6 (Anthropic) n’est pas équivalent à un GPT-5 (OpenAI), ni en capacité, ni en tarif, ni en style. Même à l’intérieur d’une famille, la différence entre Haiku (rapide, pas cher) et Opus (profond, cher) peut atteindre 5× en prix, sur des cas d’usage où Haiku suffisait largement.
Exemple concret (avril 2026, ordres de grandeur). Un agent service client qui traite 1 000 conversations par jour — en moyenne 1 500 tokens d’entrée (message + contexte + base de connaissances) et 250 tokens de sortie par conversation. En Haiku 4.5 : ~80 €/mois. En Opus 4.6/4.7 : ~375 €/mois. ~5× de différence, même agent, même prompt, même qualité perçue dans 95 % des cas de service client — où Opus est objectivement du gaspillage.
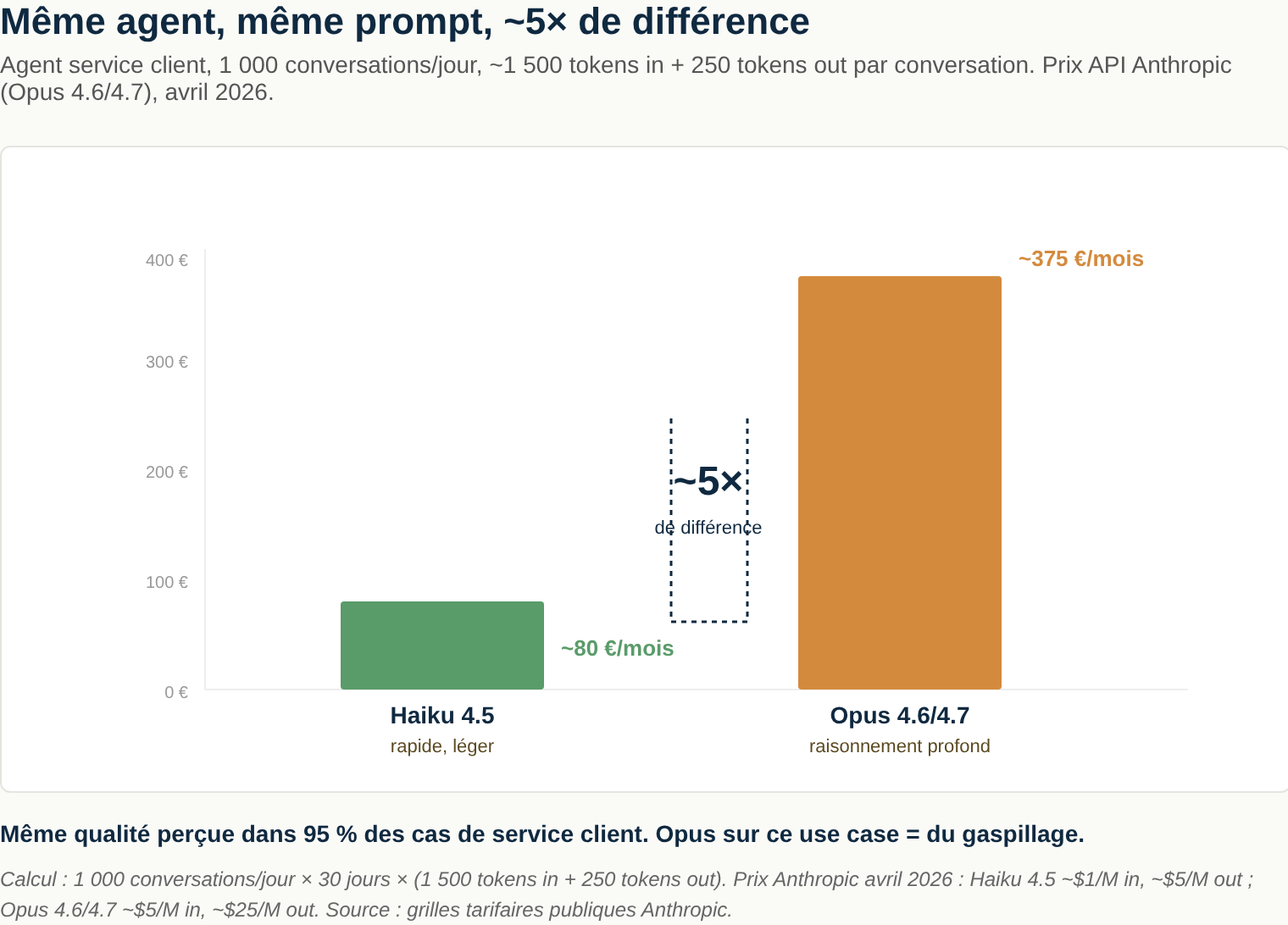
La règle procurement : ne jamais acheter « du Claude » ou « du ChatGPT ». Acheter un modèle précis pour un cas d’usage précis. Un agent qui fait de la catégorisation de factures n’a pas besoin d’Opus. Un outil d’analyse juridique contractuelle ne doit probablement pas tourner sur Haiku.
Si vous n’avez pas ce niveau de granularité dans votre conversation vendor, vous payez le plus cher par défaut. Et les commerciaux des éditeurs n’iront pas vous proposer spontanément de migrer 70 % de vos usages sur un modèle 10× moins cher.
Subscription vs API : les deux visages du coût IA
C’est là que 80 % des dérapages se produisent. Il y a deux manières d’acheter de l’IA, et elles n’ont rien à voir côté risque financier.
La subscription (abonnement). Vous payez un forfait par mois, par utilisateur. Claude Pro à 20 $/mois, ChatGPT Enterprise à ~60 $/mois par seat, etc. Plafond fixe, consommation limitée, l’utilisateur est bloqué quand il atteint sa quota. C’est le modèle prévisible, transparent, et relativement safe côté finance. C’est aussi celui que la majorité des équipes utilisent aujourd’hui pour de l’assistant individuel en navigateur ou app.
Pour donner un ordre de grandeur concret — ce que 20 € et 100 € par mois vous donnent en avril 2026 :
| Budget/mois | Mode | Anthropic | OpenAI | |
|---|---|---|---|---|
| ~20 € | Subscription | Claude Pro — ~1-2 M tokens équivalents | ChatGPT Plus — ~1-2 M tokens équivalents | Gemini Advanced — ~2-3 M tokens équivalents |
| ~20 € | API pay-as-you-go | Sonnet 4.6 — ~2 M tokens | GPT-5 — ~3 M tokens | Gemini 2.5 Pro — ~6 M tokens |
| ~100 € | Subscription | Claude Max 5× — ~5-10 M tokens | ChatGPT Business (seats) — variable | Gemini Advanced multi-seats |
| ~100 € | API pay-as-you-go | Sonnet 4.6 — ~10 M tokens | GPT-5 — ~16 M tokens | Gemini 2.5 Pro — ~32 M tokens |
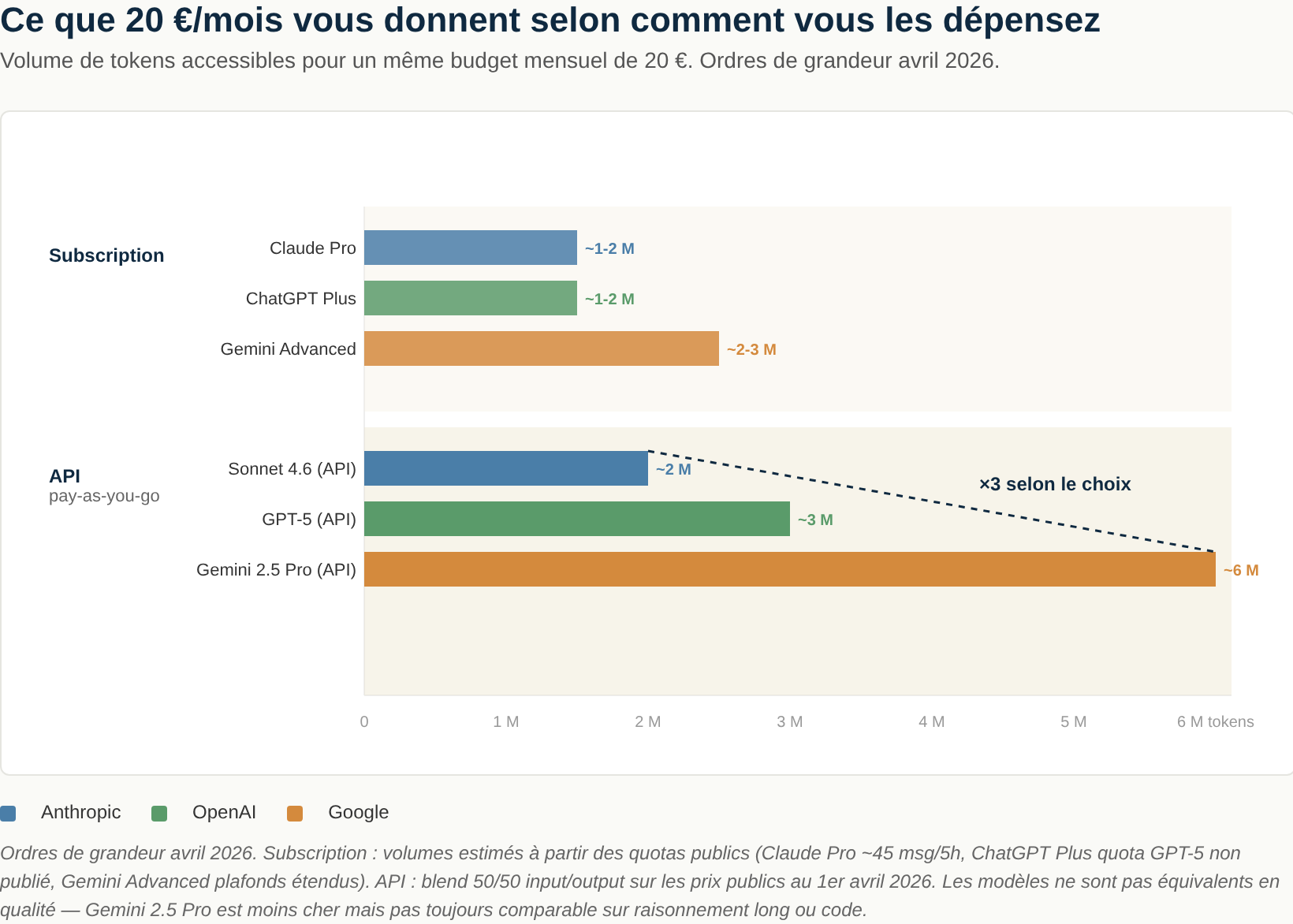
Ce qu’il faut retenir : passé un certain volume, l’API bat systématiquement la subscription en €/token — sauf à accepter les plafonds d’usage individuels. Le vrai choix n’est pas « API vs subscription », c’est « quel mix pour quel profil d’utilisateur ».
L’API. Vous ne payez plus par utilisateur. Vous payez au token consommé. Les logiciels de votre boîte — agents internes, automatisations, chatbots clients, scripts data — appellent l’API directement. Pas de seat. Pas de plafond. Pas d’utilisateur humain pour s’arrêter quand ça dérape. C’est là que se créent les factures à 6 chiffres.
Regardez juste les posts LinkedIn des fondateurs qui affichent fièrement leur facture OpenAI à 100 k$+ pour 5 employés. Cela pourrait être un vrai signal d’alerte. Un agent mal calibré peut consommer des milliers d’euros en quelques heures. Le nombre d’histoires de ce type explose :
- Un dev lance un agent de scraping avec un prompt mal écrit — l’agent s’appelle lui-même en boucle toute une nuit. Facture du matin : 34 000 $.
- Une équipe marketing qui teste un outil de génération de contenu, avec un template par défaut qui envoie l’intégralité du site web en contexte à chaque requête. 800 $ par jour, pendant trois semaines, avant que quelqu’un ne remarque.
Règle de gouvernance : quiconque dans votre organisation a accès à une clé API doit avoir un budget cap technique (pas juste contractuel). Alerte à 50 %, 80 %, kill switch automatique à 100 %. Sans ça, vous jouez à la roulette avec votre P&L.
Cette règle, personne ne l’applique par défaut. C’est une décision explicite à prendre, idéalement portée conjointement par procurement, finance, et la DSI. Sinon ça n’existe pas.
Les leviers d’optimisation : routers, open source, bon modèle pour le bon job
Les AI routers. Un router, c’est une couche logicielle qui envoie chaque requête au modèle le plus approprié (ou le moins cher à qualité visée) en temps réel. Si Claude est down, bascule sur GPT-5. Si la requête est simple, route vers Haiku plutôt que vers Opus. Si un modèle open source auto-hébergé suffit, utilise-le en priorité. C’est aussi un terrain d’expérimentation : mêmes requêtes envoyées à 3 providers, comparaison des résultats, choix data-driven.
OpenRouter, LiteLLM, Portkey, et quelques autres dominent ce segment en 2026. Pour une organisation qui dépense plus de ~100 k€/an en IA, ce n’est plus optionnel : c’est hygiène de base. Réductions observées : 30 à 60 % à qualité équivalente, plus la résilience en cas de panne d’un fournisseur — ce qui est arrivé plusieurs fois chez chacun des grands acteurs en 2025.
Les modèles open source. Llama (Meta), Mistral (français, cocorico !), DeepSeek, Qwen et quelques autres offrent des modèles de qualité surprenante, souvent à coût marginal très faible si vous les auto-hébergez. L’idée est de ne pas avoir de coûts par token direct, mais construire sa propre capacité à traiter les besoins. Ce n’est pas toujours pertinent — l’auto-hébergement coûte du temps d’ingénierie, de l’infra GPU, et de l’expertise ML. Mais sur les cas d’usage volumiques et répétitifs (catégorisation, extraction, classification, RAG sur données internes), un Mistral fine-tuné peut remplacer Claude Sonnet pour 1/20 du coût, avec une latence inférieure et vos données qui ne sortent pas de vos serveurs. Si vous avez une équipe data ou ML mature, c’est probablement votre plus gros levier en 2026.
Le principe général : l’IA la moins chère qui fait le job, c’est la bonne. Pas la plus puissante. Pas la plus à la mode sur X. Celle qui fait le job à qualité acceptable pour le coût minimum. Ce principe banal en procurement classique est, bizarrement, oublié par tout le monde dès qu’on parle d’IA. Probablement parce que le sujet est encore perçu comme tech / stratégique / innovation, alors qu’il est en train de devenir une ligne budgétaire comme une autre. Qui va juste 10× plus vite que les autres.
Les outils pour t’aider : le marché émergent du SaaS/AI FinOps
Un nouveau marché émerge en 2025-2026 : les plateformes spécialisées dans le spend management IA et SaaS. Parce qu’entre les abonnements IA, les abonnements SaaS traditionnels (qui eux-mêmes intègrent de plus en plus de briques IA facturées séparément), les coûts API, les licences utilisateurs et les overages, plus personne ne sait qui paye quoi. Trois acteurs valent le coup d’être connus :
- Spendhound (US) — gratuit pour le client. Vous branchez vos comptes fournisseurs SaaS, l’outil vous dit quels renouvellements arrivent, quels benchmarks prix existent sur le marché, et quels leviers de négo vous avez. Attention au modèle économique : Spendhound est adossé à une société marketing qui monétise les « sentiments » clients collectés sur les vendors. Ce n’est pas un problème en soi — c’est même comme ça que Gartner et G2 fonctionnent — mais c’est à avoir en tête avant de partager vos données contractuelles.
- Vertice (UK, prétendant sérieux au statut de licorne) — payant, mais « white glove » : leur équipe négocie elle-même vos contrats SaaS et IA à votre place, en s’appuyant sur des benchmarks massifs issus de leurs autres clients. ROI souvent supérieur au coût sur les boîtes avec > 5 M€ de spend SaaS annuel.
- Najar (français, ex-Welii) — alternative européenne en croissance, positionnement pragmatique, utile si vous cherchez un acteur dans votre juridiction RGPD et un contact local.
Ou l’option humaine premium : vous faites appel à un consultant procurement qui comprend ces technologies, peut vous aiguiller sur les bons choix et vous aider à optimiser vos contrats — plafonds d’engagement sur consommation API, clauses de portabilité des données, droit d’audit sur les logs d’usage, clauses de sortie propres, réversibilité vers concurrent. Pour discuter : alex@theprocurementor.com. 😉
Si votre organisation commence à voir ses coûts IA déraper et que vous voulez un regard externe procurement × tech : alex@theprocurementor.com.